
It will read the text from PDF in python. Read Tables of PDF and place the data to XLSX
file and read the XLSX file to one by one.
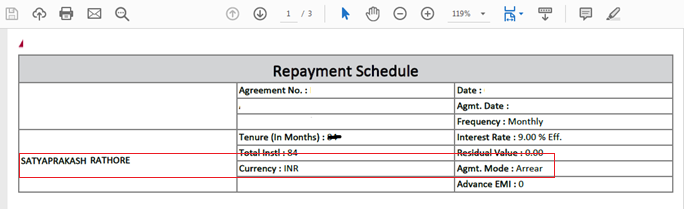
Suppose you are having the PDF file like below.
It’s a PDF file for Home loan, using the pdftables_api it
will use to convert the PDF File into the form of xlsx file.
Now it will convert the PDF file into XSLX.

Based on the Pages of PDF it will generate into sheet
number, if there are 2 pages of PDF than it will generate to 2 sheet in XSLS file.
Code to convert the PDF Tables into Xslx file
|
#1. Importing the PDf
table API
# Pip Insta the Pdftable api as
# pip install
https://github.com/pdftables/python-pdftables-api/archive/master.tar.gz
# https://pdftables.com/blog/pdf-to-excel-with-python
import pdftables_api
#pip install xlrd
# Importing the data to excel
# ref :
https://www.geeksforgeeks.org/reading-excel-file-using-python/
import xlrd
apikey = ''
c = pdftables_api.Client(apikey)
c.xlsx(r'C:\Users\reet\Desktop\loan sheet\PHR000802187754.pdf',
'output.xlsx')
# Read the workbook one by one
loc = ("output.xlsx")
wb = xlrd.open_workbook(loc)
sheet = wb.sheet_by_index(0)
sheet.cell_value(0, 0)
#Read row number 7
print(sheet.row_values(7))
|
Lets go in details if of PDF tables into XLSX you need to do
the pip install for below and import it into code
|
pip install
https://github.com/pdftables/python-pdftables-api/archive/master.tar.gz
|
You need to provide your API keys here
|
apikey = ''
|
You need to install the xlrd to read the xlsx file.
|
pip install xlrd
|
You need to provide the location of xlsx file as in below
|
loc = ("output.xlsx")
wb = xlrd.open_workbook(loc)
|
Now read the XLSX file coloum and row of excel file
generated by PDF from python code by below code.
|
#Read row number 7
print(sheet.row_values(7))
|
You will get output of that will be just check red border line content

I got many useful informations about this topic from your blog. Really very useful for learning the skills
ReplyDeleteAngularJS Training in Tambaram
AngularJS Training in Porur
AngularJS Training in Velachery
Angularjs Training in chennai
AngularJS Training in T Nagar
Web Designing Training in OMR
Web Designing Training in T Nagar
Web Designing Training in Tambaram